- The Deep View
- Posts
- After 6 years of secrecy, OpenAI releases free AI models
After 6 years of secrecy, OpenAI releases free AI models
The Deep View
August 06, 2025


Welcome back. Elon Musk and X just defeated California's strictest deepfake law in federal court—the same law Gov. Gavin Newsom signed specifically to rebuke Musk after he shared that doctored Kamala Harris video. The judge struck it down using Section 230 protections rather than free speech arguments, which is probably not the constitutional victory lap Musk was hoping for, but a win's a win.
1. OpenAI's open-weight gambit rewrites the AI playbook
2. Anthropic releases Claude Opus 4.1 to compete with GPT-5
3. OpenAI's data standoff exposes the hidden cost of AI lawsuits
FRONTIER AI
OpenAI's open-weight model rewrites the AI playbook

After six years of exclusively proprietary releases, OpenAI dropped gpt-oss-120b and gpt-oss-20b under the permissive Apache 2.0 license — a decision that fundamentally alters competitive dynamics.
Unlike Meta's Llama license, which requires paid agreements for services exceeding 700 million monthly users (a massive scale, but still restrictive), Apache 2.0 imposes no such limitations. Companies can download, modify, commercialize and redistribute freely.
Both models use a mixture-of-experts architecture with aggressive quantization. Rather than activating all 117 billion parameters, gpt-oss-120b uses only 5.1 billion parameters per token — essentially routing each query through specialized sub-networks while keeping most parameters dormant. This enables the model to run on a single 80GB GPU instead of requiring massive clusters. The smaller gpt-oss-20b needs only 16GB of memory.
Performance benchmarks position these models competitively with OpenAI's proprietary offerings (the paid, API-accessible models that generate most of the company's revenue through subscription fees and per-token pricing). Gpt-oss-120b matches o4-mini on core reasoning tasks, while gpt-oss-20b rivals o3-mini despite its smaller size.
OpenAI conducted extensive safety testing, including adversarial fine-tuning to simulate potential misuse. The company filtered harmful Chemical, Biological, Radiological, and Nuclear (CBRN) data during pre-training and used instruction hierarchy techniques to defend against prompt injections. External red teams submitted 110 attack attempts, with researchers testing everything from biosecurity information extraction to chain-of-thought manipulation. OpenAI also launched a $500,000 Red Teaming Challenge to crowdsource vulnerability discovery.
Sam Altman explicitly framed gpt-oss as ensuring "the world is building on an open AI stack created in the United States, based on democratic values," directly addressing the Chinese AI surge that has challenged Silicon Valley's dominance.
Rather than viewing open-weight releases as revenue cannibalization, the company recognizes them as market expansion tools. Developers who fine-tune gpt-oss models remain within OpenAI's ecosystem, potentially upgrading to proprietary services for advanced capabilities.
Once released, OpenAI loses control entirely. Bad actors could potentially fine-tune for harmful purposes, and competitors could gain access to OpenAI's training techniques. But that goes with any open-source software
Like Amazon's AWS strategy of democratizing foundational infrastructure to drive premium service adoption, giving away capable models could define how frontier AI companies balance openness with commercial interests. The company's long road to profitability — expecting $44 billion in losses through 2028 — makes this platform play essential for long-term survival.
TOGETHER WITH SNYK
Live Virtual Workshop: Securing Vibe Coding

Join Snyk's Staff Developer Advocate Sonya Moisset on August 28th at 11:00AM ET covering:
✓ How Vibe Coding is reshaping development and the risks that come with it
✓ How Snyk secures your AI-powered SDLC from code to deployment
✓ Strategies to secure AI-generated code at scale
Earn 1 CPE Credit!
MODEL IMPROVEMENTS
Anthropic releases Claude Opus 4.1 to compete with GPT-5

Hours after OpenAI's major announcement, Anthropic quietly released Claude Opus 4.1 — a move that speaks volumes about how the company views competition in the AI race.
Unlike the splashy launches we've grown accustomed to, Opus 4.1 represents what CEO Dario Amodei calls a "drop-in replacement" for developers already using Opus 4. The improvements are real but narrow: coding performance climbs from 72.5% to 74.5% on SWE-bench Verified, while agentic terminal tasks jump from 39.2% to 43.3% on Terminal-Bench.
But the model's performance isn't universally better. On TAU-bench's airline task, Opus 4.1 actually declined to 56.0% from Opus 4's 59.6%, falling behind even the smaller Claude Sonnet 4 at 60.0%. These mixed results suggest Anthropic optimized for specific use cases rather than pursuing across-the-board improvements.
This targeted approach reflects a company playing a different game entirely. While competitors chase headlines with revolutionary capabilities, Anthropic positions itself as the reliable choice for enterprise customers who value consistent, incremental progress over dramatic leaps.
GitHub integrated the model into Copilot within hours, though Opus 4 will be deprecated in just 15 days
Pricing remains identical at $15/$75 per million tokens, making this one of the market's most expensive models
The release emphasizes safety testing and responsible deployment practices, consistent with Anthropic's brand positioning
The timing raises strategic questions. With GPT-5 expected later this month, Anthropic faces pressure to demonstrate continued innovation. Yet rather than rushing a dramatic capability jump, the company doubled down on its methodical approach.
This conservative strategy may reflect Anthropic's smaller scale — the company reported $5 billion in annual recurring revenue compared to OpenAI's $13 billion — but it also suggests confidence in differentiation through reliability rather than raw performance.
Whether measured improvements can compete with transformational promises remains the defining question for Anthropic's future market position.
TOGETHER WITH GUIDDE
Simplify Training with AI-Generated Video Guides

Are you tired of repeating the same instructions to your team? Guidde revolutionizes how you document and share processes with AI-powered how-to videos.
Here’s how:
Instant Creation: Turn complex tasks into stunning step-by-step video guides in seconds.
Fully Automated: Capture workflows with a browser extension that generates visuals, voiceovers, and call-to-actions.
Seamless Sharing: Share or embed guides anywhere effortlessly.
The best part? The browser extension is 100% free.
LEGISLATION
OpenAI's data standoff exposes the hidden cost of AI lawsuits

When a respected computer scientist says 20 million private conversations should be enough for analysis, and you demand 120 million instead, something has gone very wrong with your legal strategy.
UC San Diego professor Taylor Berg-Kirkpatrick — a natural language processing expert with over 10,000 academic citations — told the court that 20 million ChatGPT logs would sufficiently prove copyright infringement patterns. The New York Times rejected this recommendation and now demands six times more user data.
20 million conversations represents more private exchanges than most people have in their entire lives, multiplied across millions of users. Yet NYT's lawyers insist they need 120 million to demonstrate "patterns of regurgitation" that help users bypass paywalls.
OpenAI has been fighting a federal court order requiring it to preserve all user conversations, including deleted chats — directly contradicting its promise to permanently delete user data within 30 days. District Judge Sidney Stein rejected OpenAI's privacy objections and affirmed the preservation order, affecting over 400 million users worldwide.
The privacy implications are staggering. Sam Altman recently warned that people share their "most personal shit" with ChatGPT — using it as a therapist, life coach, and confidant — but these conversations lack legal confidentiality protections. Discovery demands like NYT's could expose the most sensitive exchanges users never expected to become public.
A settlement conference is scheduled for August 7, but only to resolve data access scope
ChatGPT Enterprise customers are excluded from the preservation order
Each conversation must be decompressed and scrubbed of identifying information before analysis
This precedent could embolden every media company to demand similar access in their own copyright fights. The message is clear: there's no such thing as private AI conversations when lawyers get involved.
LINKS

OpenAI in talks for share sale at $500b valuation
U.S. charges two Chinese nationals for illegally shipping Nvidia AI chips to China
Grok’s ‘spicy’ video setting instantly made me Taylor Swift nude deepfakes
Wikipedia editors adopt ‘speedy deletion’ policy for AI slop articles
Google’s new AI model creates video game worlds in real time
Voice startup ElevenLabs launches AI music service
Runway, Luma in talks for multibillion-dollar fundraises as revenue picks up
Microsoft’s new AI reverse-engineers malware autonomously
Gemini app can now create custom storybooks, comics and more
Qwen launches new Image, a new open-source AI image generator with support for embedded text in English & Chinese

Manus Wide Research: AI agents that collaborate to tackle complex research
SciSpace Agent: AI assistant to automate everyday research tasks
Verbite: AI tool to create SEO content
Clueso: Product videos in minutes with AI



A QUICK POLL BEFORE YOU GO
Is OpenAI's open-weight release a masterstroke or mistake? |
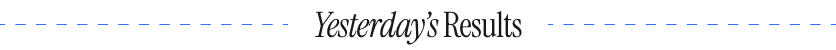
 | “[The other image] has a random tree growing from the roof in the middle of the picture, plus another "ghost" tree lower right.” “The mismatching buildings and materials are very typical of an old city. The other picture was not as sharp and just didn't look real.” |
 | “While I assumed it wasn't [the other image] because the church didn't look natural sandwiched between the buildings, it did seem more realistic because of the coloring. [This image] looked more real but did have the appearance that it had been processed by someone who knows photography.” “I picked b cause the composition on the other was awful :)” |
The Deep View is written by Faris Kojok, Chris Bibey and The Deep View crew. Please reply with any feedback. Thanks for reading today’s edition of The Deep View! We’ll see you in the next one.
Take The Deep View with you on the go! We’ve got exclusive, in-depth interviews for you on The Deep View: Conversations podcast every Tuesday morning.
If you want to get in front of an audience of 450,000+ developers, business leaders and tech enthusiasts, get in touch with us here.